To compress it down to less than 2gb would require a type of black magick even Microsoft isn't able to produce.

I am using Windows 2012 data deduplication, which is a new technology that saves disk space by looking at each block on the disk and if there are multiple blocks that are the same it only saves one copy. So, if you have several copies of the same file, even if they are a little bit different from each other, or if you have files with lots of repetition (like log files), it can save you lots of space.
Because I'm using Windows data deduplication, the size on disk only shows the size of the metadata. With PowerShell's Measure-DedupFileMetadata command I can get the actual space used.


Adding the SavedSpace shown with Get-DedupStatus to the DedupSize shown by Measure-DedupFileMetadata indeed does add up to 721.26... just short of the Size of 722.68GB reported by the Measure-DedupFileMetadata and 722GB reported by the GUI. Given a margin of error on that calculation to account for rounding, that seems right to me.
Ok, so it didn't shrink it down to 2GB like the teaser might have lead you to think, but shrinking 722GB down to 484 GB is pretty impressive still, that's about a 33% savings. With a volume size as large as this (yup that says 20TB, but it's not real, we'll get to that in a later post) NTFS can no longer do file compression (NTFS file compression is not possible on drives that have a larger cluster size than 4K), but the new data deduplication applied at the volume level makes decently efficient use of space.
By now you are probably starting to see why it's suddenly important to start learning about PowerShell, if you haven't already started. The Windows GUI will no longer be sufficient to properly administer newer versions of Windows. For the past several years it was necessary for Exchange Server admins to get the most out of that product, and for Server Core editions of Windows Server to be manageable at their own console, but now newer features like Disk Deduplication and Storage Pools, require it in order to get the most out of these features. Much like Linux and Cisco, Windows is headed to an age where those who understand it's command line will be able to do much more, and do it much more efficiently, than those who only learn it's graphical interface.
So how do you go about setting up deduplication?
For starters, you need a separate disk from your OS boot disk. (you can't dedup c:)
You can install it via the old fashioned GUI:
Go into Server Manager
Click "Manage"
Click "Add Roles and Features"
Work your way down to "Server Roles"
Under "File and Storage Services", enable "Data Deduplication"

or, just open PowerShell and type:
"Import-Module ServerManager"
"Add-WindowsFeature -name FS-Data-Deduplication"
Enable it on a volume via the GUI:
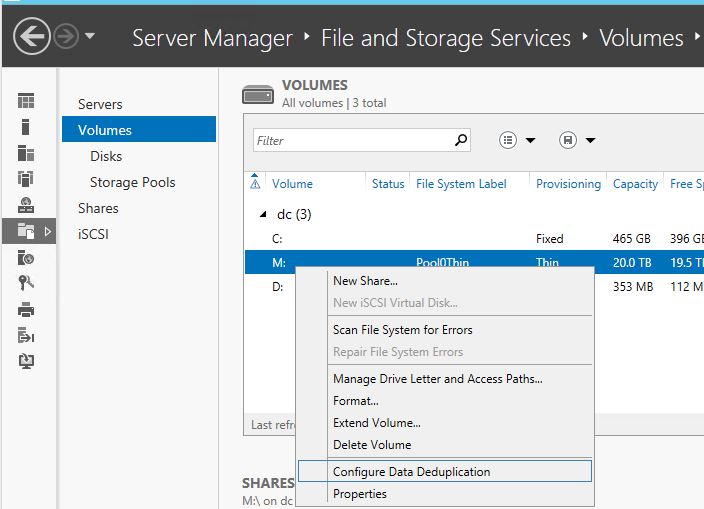
In the Server Manager, select "File and Storage Services", and then "Volumes".
Right click on a volume, and select "Configure Data Deduplication"
or, via PowerShell:
"Enable-DedupVolume M:"
In the next post I will get into the details of Storage Pools. This is a really neat feature of Windows 8 and 2012 that puts the old RAID system to shame.


No comments:
Post a Comment